반응형
1. sudo apt update
2. sudo apt install default-jdk
3. java -version
반응형
'설치,명령어등 > ubuntu' 카테고리의 다른 글
| ubuntu Chorme 설치 (0) | 2021.01.05 |
|---|---|
| anaconda 해당 환경 export 및 설치방법 (0) | 2021.01.04 |
1. sudo apt update
2. sudo apt install default-jdk
3. java -version
| ubuntu Chorme 설치 (0) | 2021.01.05 |
|---|---|
| anaconda 해당 환경 export 및 설치방법 (0) | 2021.01.04 |
준비물-> centos 7 // vertual box //
# 버츄얼박스 네트워크 설정 ( 호스트 네트워크 관리자)
## 파일-호스트네트워크 관리자로 들어간다
##virtualBox Host-Only Ethernet Adapter 클릭->아래 어댑터 탭에서 설정시작
$ip route # -> 게이트웨이 확인(default에 나오는 값)
1.수동으로 어댑터 설정
2. ipv4 주소= 192.168.56.1
3. ipv4 서브넷 마스크 = 255.255.255.0
4. dhcp 체크해제
적용
# 버츄얼박스 os(centos 7 이미지생성/ 최소 2개 생성/용량30gb/cpu코어 2코어 이상 만들것)
## 이미지우클릭 - 설정 - 네트워크
1. 1번 어댑터는 NAT로 설정
2. 2번 어댑터는 호스트 전용 어댑터를 클릭
3. 1번 어댑터 -고급-포트포워딩//
포트 포워딩 규칙 추가 한다. (추후 ssh, web 외부 접속을 위해 22, 80포트)
## master로 쓸 vm image에서 수정
- 호스트ip 192.168.56.1
- 호스트 port 22
- 게스트ip 192.168.56.150
- 게스트 port 22
## node로 쓸 이미지도
- 호스트 ip 위와 동일
- port 23
- 게스트 ip: 192.168.56.151
- 게스트port 23
혹시 호스트 ip 찾는법 모르시는 분을 위해서 아래의 url을 참고
# 설정후 os설치https://respecttt.tistory.com/51
버츄얼박스 host ipv4 주소 알아내는 법 / virtual box ip 보는법
광고한번씩 클릭 해 주시면 있던 오류도 사라질 겁니다.! 큰 도움이 됩니다. 한번씩만 클릭 부탁드리겠습니다.ㅠㅠㅠㅠ 버츄얼 머신을 실행시키면 버츄얼 머신과 네트워킹 하는 ip를 할당하게
respecttt.tistory.com
*버츄얼 박스 마스터 이미지
#centos 설치 후
(moba XTerm으로 ssh로 접속한다.)
ex) root@192.168.56.1:22
(master이미지 설정)
* network설정
cd /etc/sysconfig/network-scripts
vi ifcfg-enp0s8 (이름이 가끔 달랐음 ex // ifcfg-enp0s3)
[master/ifcfg-enp0s8]
#2개 변경
BOOTPRTO=static
ONBOOT=yes
# 맨 아래에 2줄 추가
IPADDR=192.168.56.150
GATEWAY=192.168.56.1
-> :wq로 저장후 빠져나옴
* hostname, hosts설정
vi /etc/hostname
[hostname]
k8s-master
-> :wq로 저장후 빠져나옴
vi /etc/hosts
[hosts]
추가
192.168.56.150 k8s-master
192.168.56.151 k8s-node1
-> :wq로 빠져나옴
$systemctrl restart network
$systemctrl reboot* 버츄얼박스 노드1 이미지 설정
위와 같으나
2가지 다른것이 있다.
1. [ipcfg-enp0s8]
IPADDR=192.168.56.151
2. [hostname]
k8s-node1
으로 설정 후 똑같이 다 해준다.본격적인 kubenetis설치
[마스터, 노드1 이미지 둘다 설치해야함]
1. 도커설치
$ curl -s https://get.docker.com | sudo sh
$ systemctl enable --now docker
2. selinux, swap, 방화벽 비활성화
$ setenforce 0
$ sed -i 's/^SELINUX=enforcing$/SELINUX=disabled/' /etc/selinux/config
$ swapoff -a
$ sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
$ systemctl disable firewalld
$ systemctl stop firewalld
3.iptables 설정
##cat부터 EOF까지 복사해서 붙혀넣기
$ cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
$ cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
$ sudo sysctl --systemkube시리즈 3개 설치
[마스터, 노드1 이미지 둘다 설치해야함]
1. repo등록.
$ cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-\$basearch
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
exclude=kubelet kubeadm kubectl
EOF
2. 설치
$ yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes
$ systemctl enable --now kubelet
daemon.json 편집
$ cat <<EOF | sudo tee /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"],
"log-driver": "json-file",
"log-opts": {
"max-size": "100m"
},
"storage-driver": "overlay2",
"storage-opts": [
"overlay2.override_kernel_check=true"
]
}
EOF
설치 완료 후 [master]에서만 입력
$ kubeadm init --apiserver-advertise-address 192.168.56.150 --pod-network-cidr=172.31.0.0/16##에러 발생시
$ rm /etc/containerd/config.toml
$ systemctl restart containerd
입력후 다시 위의 명령어로 initinit이 완료된 커멘드창을 자세히 보면
mkdir -p $HOME/.kube로 시작되는 메세지 부터 3개를 각각 입력해준다.
그리고 export KUBECONFIG으로 시작하는 명령어도 입력하여
총 4개의 명령어를 추가로 입력해준다.
그리고 조금 아래에 보면 kubeadm join 으로 시작하는 메세지도 복사한다.// 토큰값까지
ex)
kubeadm join 192.168.56.150:6443 --token au8frb.4deses4x2qq6debo --discovery-token-ca-cert-hash sha256:303378599aca0206f994607e584a9a2dc2ab74131020e4b4fd1956f2dad6ba89
그리고 node1 이미지에서
복사한 kubeadm join ~ 을 붙혀넣기 하여 master node에 join 시킨다.
[master]
$ kubectl get nodes를 쳐서 노드가 클러스터에 참여하는지 확인한다.
[weave]
$ kubectl apply -f https://github.com/weaveworks/weave/releases/download/v2.8.1/weave-daemonset-k8s.yaml다른 쿠버네티스 설치를 보면 weave설치할때 다운이 안받아져서 계속 에러가 나는데 git으로 주소를 바꾼듯 하다.
네임스페이스 확인
$kubectl get pods --all-namespaces
설치시 내가 많이 햇갈렸던 부분은 네트워킹이다.
네트워킹 관련하여 잘 몰라서 여러번 삽질을 한것.
그리고 weav추가가 잘 안되서 찾아보니 git으로 주소가 바꼈었던것.
1. 버츄얼박스에서 각 이미지들간의 통신을 어떻게 설정할 것인가?
2. os안에서 ip설정 및 hosts 설정등
설치 끝...?
아. 추가로 설치 실패시
$ kubeadm reset
$ systemctl restart kubelet
$ systemctl reboot광고한번씩 클릭 해 주시면 있던 오류도 사라질 겁니다.!
큰 도움이 됩니다. 한번씩만 클릭 부탁드리겠습니다.ㅠㅠㅠㅠ
버츄얼 머신을 실행시키면 버츄얼 머신과 네트워킹 하는 ip를 할당하게 된다.
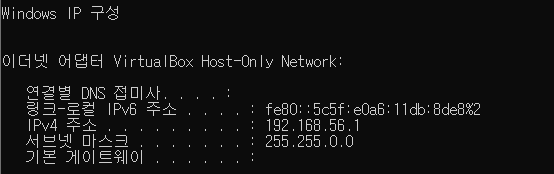
윈도우즈커멘드창을 키고 ipconfig명령어를 치면
windows ip 구성이 아래와 같이 나오는데
이더넷 어댑터 VirtualBox host의 칸을 보고 ipv4주소를 알아낼 수 있다.
node-red를 활용하여 3개의 topic을 만들고 각각의 토픽에 랜덤 변수를 5초간격으로 송, 수신하는 node-red를 만들어라.
## 이전 포스트를 보고 kafka가 설치 되어있어야 한다.
Node.js
Node.js® is a JavaScript runtime built on Chrome's V8 JavaScript engine.
nodejs.org
설치.(stable버전)
https://flows.nodered.org/node/node-red-contrib-kafka-manager
node-red-contrib-kafka-manager
Node-RED implements Kafka manager with associand associated .
flows.nodered.org
$ npm install kafka-node
<kafka내장 주키퍼로 시작>
$ zookeeper-server-start.sh -daemon /root/kafka/config/zookeeper.properties
$ yum install telnet
<엑세스 여부 확인>
$ telnet localhost 2181
<기본속성으로 kafka를 시작>
$ kafka-server-start.sh -daemon /root/kafka/config/server.properties
<9092 확인>
$ telnet localhost 9092
<샘플 주제를 만든다>
$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic1
$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic2
$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic topic3
<작성된 주제 나열>
$ kafka-topics.sh --zookeeper localhost:2181 --list
#topic 1,2,3뜨면 됨
구성은 이렇게 해봤고,
node-red에서 최초 inject를 잡아주고, 그다음 필요한 각각의 input을 넣어 프로세스를 잡아준다. 최종적으로 kafka_producer로 향하게 노드를 그린다.
# 설정은 필요에 따라 다르게 하고, Topic부분에 아까 써줬던 topic1,2,3을 각각 잡아주고
broker부분에 연필모양을 눌러서 hosts를 vm으로 잡아준다. (192.168.56.1 : 9092)
그리고 전송이 잘 되었는지 확인 하기 위해 debug consol을 활용하여 로그를 확인한다.
마지막으로 producer와 같이 consumer를 생성한뒤, 각각의 토픽명들을 적어주고, 브로커를 똑같이 잡아주고, 콘솔도 추가해준다.
마지막으로 deploy를 눌러 시작하고 오른쪽의 debug를 눌러 로그를 확인한다.
기호에 따라 inject부분에 interval을 줘서 계속 데이터가 들어오는지 확인한다.
끝.
| kafka 테스트/실습 (0) | 2022.03.04 |
|---|---|
| kafka 설치/ (0) | 2022.03.02 |
intellij(java) -> consumer/ producer 파일생성 및 log파일 생성후 vm 카프카에 데이터를 송/수신
intellij>


의존성 추가!!
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>1.1.0</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.11</artifactId>
<version>0.8.2.1</version>
</dependency>
consumer 작성
package kafkaTutorial;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
public class Consumer {
public static void main(String[] args) {
Properties configs = new Properties();
// 환경 변수 설정
configs.put("bootstrap.servers", "192.168.56.1:9092"); // kafka server host 및 port
configs.put("session.timeout.ms", "10000"); // session 설정
configs.put("group.id", "!!!!!!변경!!!!!"); // topic 설정
configs.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // key deserializer
configs.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); // value deserializer
KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(configs); // consumer 생성
consumer.subscribe(Arrays.asList(""!!!!!!!!변경!!!!!");")); // topic 설정
while (true) { // 계속 loop를 돌면서 producer의 message를 띄운다.
ConsumerRecords<String, String> records = consumer.poll(500);
for (ConsumerRecord<String, String> record : records) {
String s = record.topic();
if (""!!!!!!변경!!!!!!!");".equals(s)) {
System.out.println(record.value());
} else {
throw new IllegalStateException("get message on topic " + record.topic());
}
}
}
}
}
producer작성
package kafkaTutorial;
import java.io.IOException;
import java.util.Properties;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
public class Producer {
public static void main(String[] args) throws IOException {
Properties configs = new Properties();
configs.put("bootstrap.servers", "192.168.56.1:9092"); // kafka host 및 server 설정
configs.put("acks", "all"); // 자신이 보낸 메시지에 대해 카프카로부터 확인을 기다리지 않습니다.
configs.put("block.on.buffer.full", "true"); // 서버로 보낼 레코드를 버퍼링 할 때 사용할 수 있는 전체 메모리의 바이트수
configs.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // serialize 설정
configs.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // serialize 설정
// producer 생성
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(configs);
// message 전달
for (int i = 0; i < 5; i++) {
String v = "hello world!"+i;
producer.send(new ProducerRecord<String, String>("!!!!!!!!변경!!!!!!!", v));
}
// 종료
producer.flush();
producer.close();
}
}
!!!!!!!변경!!!!!!!!!!부분 kafka 설정한 topic으로 변경하기
main->resources->log4j.properties // 폴더트리 만들어주고 파일생성-log4j만든다.
<log4j>
$ cat src/main/resources/log4j.properties
# Root logger option
log4j.rootLogger=DEBUG, stdout
# Direct log messages to stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %-5p %c{1}:%L - %m%n
마지막으로 vm으로 돌아가서
1. 카프카 멈춰주고
2. kafka - conf - server.properties를 vim으로 열어서 (맨위에 그냥 추가한다.주석처리 찾아서 해도됨)
advertised.listeners=PLAINTEXT://192.168.56.1:9092
listeners=PLAINTEXT://0.0.0.0:9092
3. 카프카 재 실행 후 consumer -> producer 차례로 실행하면 hello world가 보인다

출처 : https://www.confluent.io/blog/kafka-client-cannot-connect-to-broker-on-aws-on-docker-etc/
Why Can’t I Connect to Kafka? | Troubleshoot Connectivity
How to troubleshoot connectivity between Kafka clients (Python, Java, Spring, Go, etc.) to Kafka on Docker, AWS, or any other machine.
www.confluent.io
| node-red // kafka (0) | 2022.03.14 |
|---|---|
| kafka 설치/ (0) | 2022.03.02 |
설치버전 1.10.0
https://archive.apache.org/dist/nifi/
Index of /dist/nifi
archive.apache.org
1. 시스템 업그레이드
$ yum -y update
2.NiFi 다운로드 후 압축 풀기
$ wget https://archive.apache.org/dist/nifi/1.10.0/nifi-1.10.0-bin.tar.gz
$ tar xvfz nifi-1.10.0-bin.tar.gz
3. 환경설정
$ readlink -f /bin/javac
-> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.262.b10-0.el7_8.x86_64 < 복사
$ vi nifi-1.10.0/bin/nifi-env.sh
-> 설정
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.322.b06-1.el7_9.x86_64
그 다음 방화벽 8080,8000포트 열어줘야하는데 방화벽을 아애 끄고 진행하였음 실습이므로.
$ ./nifi-1.10.0/bin/nifi.sh start
$ nifi-1.10.0/bin/nifi.sh status
(포트 8000으로 변경)
$ vim nifi-1.10.0/conf/nifi.properties
137번줄 nifi.web.http.port=8000 으로 변경
192.168.56.1:8000/nifi/
접속 성공
출처 : https://velog.io/@modsiw/CentOS-7%EC%97%90-NiFi-%EC%84%A4%EC%B9%98%ED%95%98%EA%B8%B0
[NiFi] CentOS 7에 NiFi 설치하기
.
velog.io
nifi 상세 설명 : https://www.popit.kr/apache-nifi-overview-and-install/
NSA의 Dataflow 엔진 Apache NiFi 소개와 설치 | Popit
Apache NiFi는 NSA(National Security Agency)에서 Apache에 기증한 Dataflow 엔진입니다. 복잡해지는 기업의 시스템들에서 신속하고, 유실 없는 데이터 전송은 점점 더 중요해 지고 있습니다. 빅데이터 시스템
www.popit.kr
kafaka version 2.0.0
$ java -version
-> 1.8.xxx
-kafka install url-
https://kafka.apache.org/downloads
아래의 예제는 /root/에서 다 실행함.
$ wget https://archive.apache.org/dist/kafka/2.0.0/kafka_2.12-2.0.0.tgz
$ tar -xzf kafka_2.12-2.0.0.tgz
<심볼릭 링크 만들기>
$ ln -s kafka_2.12-2.0.0 kafka
$ echo "export PATH=$PATH:/root/kafka_2.12-2.0.0/bin" >> ~/.bash_profile
$ source ~/.bash_profile
<kafka내장 주키퍼로 시작>
$ zookeeper-server-start.sh -daemon /root/kafka/config/zookeeper.properties
$ yum install telnet
<엑세스 여부 확인>
$ telnet localhost 2181
<기본속성으로 kafka를 시작>
$ kafka-server-start.sh -daemon /root/kafka/config/server.properties
<9092 확인>
$ telnet localhost 9092
<샘플 주제를 만든다>
$ kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic tecmint
<작성된 주제 나열>
$ kafka-topics.sh --zookeeper localhost:2181 --list
출처 : https://ko.linux-console.net/?p=381
| node-red // kafka (0) | 2022.03.14 |
|---|---|
| kafka 테스트/실습 (0) | 2022.03.04 |
버전
hive 3.1.2
mariadb 10.3.xx
mysql-connector-java 8.0.26
java : jdk 8(1.8.0)
hadoop.3.1.1
java, hadoop은 앞서 적어논 게시글을 따라왔다면 깔려있다.
이제 hive를 올려볼 차례다
그전에 앞서 mariadb 다운로드하기
출처
https://zetawiki.com/wiki/CentOS7_MariaDB_%EC%84%A4%EC%B9%98
CentOS7 MariaDB 설치 - 제타위키
다른 뜻에 대해서는 CentOS6 MariaDB 설치 문서를 참조하십시오. 다른 뜻에 대해서는 우분투 MariaDB 설치 문서를 참조하십시오. 1 개요[ | ] ✔️ CentOS 7.6에서 테스트하였습니다. 리눅스 MariaDB 설치
zetawiki.com
<mariadb>
$ mkdir /mariadb_home
$ cd mariadb_home
$ vi /etc/yum.repos.d/MariaDB.repo
[mariadb]
name = MariaDB
baseurl = http://yum.mariadb.org/10.3/centos7-amd64
gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB
gpgcheck=1
$ yum install MariaDB -y
$ rpm -qa | grep MariaDB
hive 설치
https://dlcdn.apache.org/hive/
Index of /hive
dlcdn.apache.org
버전 맞게 -> bin 링크 따오기
$ mkdir /hive_home
$ cd /hive_home
$ wget https://dlcdn.apache.org/hive/hive-3.1.2/apache-hive-3.1.2-bin.tar.gz편의를 위해 /usr/local에 압축품
$ tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /usr/local/
사용자 환경설정
$ vi ~/.bashrc
###추가###
export HIVE_HOME=/usr/local/apache-hive-3.1.2-bin
PATH="$HOME/.local/bin:$HOME/bin:$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin"
export PATH
###추가###$ hadoop dfs -mkdir /tmp
$ hadoop dfs -mkdir -p /user/hive/warehouse
$ hadoop dfs -chmod g+w /tmp
$ hadoop dfs -chmod -R g+w /user[mariadb]
$ systemctl start mariadb
$ /usr/bin/mysqladmin -u root password '1234'
$ netstat -anp | grep 3306
$ mysql -u root -p
# 접속확인
$ quit
$ systemctl set-environment MYSQLD_OPTS="--skip-grant-tables"
$ systemctl start mariadb
$ systemctl status mariadb
$ mysql -u root
mariadb -> FLUSH PRIVILEGES;
mariadb -> ALTER USER 'root'@'localhost' IDENTIFIED BY '1234';
mariadb -> FLUSH PRIVILEGES;
$ systemctl stop mariadb
$ systemctl unset-environment MYSQLD_OPTS
$ systemctl start mariadb
$ systemctl status mariadb
mariadb> CREATE DATABASE metastore DEFAULT CHARACTER SET utf8;
mariadb> CREATE USER 'hive'@'localhost' IDENTIFIED BY '1234';
mariadb> GRANT ALL PRIVILEGES ON metastore.* TO 'hive'@'localhost';
mariadb> FLUSH PRIVILEGES;
mariadb> SELECT Host,User FROM mysql.user;
mariadb> SELECT SCHEMA_NAME, DEFAULT_CHARACTER_SET_NAME
-> FROM INFORMATION_SCHEMA.SCHEMATA;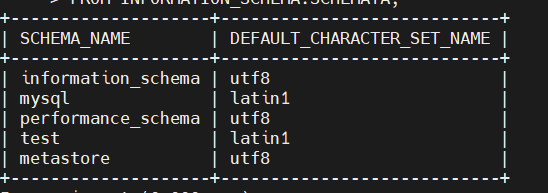
조회되면 exit
<mysql 커넥터 설치하기 !>
1. 버전확인하기
https://dev.mysql.com/doc/connector-j/5.1/en/connector-j-versions.html
MySQL :: MySQL Connector/J 5.1 Developer Guide :: 2 Connector/J Versions, and the MySQL and Java Versions They Require
Chapter 2 Connector/J Versions, and the MySQL and Java Versions They Require Two versions of MySQL Connector/J are available: Connector/J 5.1 is a Type 4 pure Java JDBC driver, which conforms to the JDBC 3.0, 4.0, 4.1, and 4.2 specifications. It provides
dev.mysql.com
2. 다운받기
https://downloads.mysql.com/archives/c-j/
MySQL :: Download MySQL Connector/J (Archived Versions)
Please note that these are old versions. New releases will have recent bug fixes and features! To download the latest release of MySQL Connector/J, please visit MySQL Downloads. MySQL open source software is provided under the GPL License.
downloads.mysql.com
$ mkdir /mysql_cnt_home
$ cd /mysql_cnt_home
8.0.26 -> indpendent -> wget
$ tar -zxvf mysql-connector-java-8.0.26.tar.gz
$ cd mysql-connector-java-8.0.26
$ mv mysql-connector-java-8.0.26.jar /usr/local/apache-hive-3.1.2-bin/lib
$ cd /usr/local/apache-hive-3.1.2-bin/conf
$ cp hive-default.xml.template hive-site.xml
bin/schematool -dbType mysql -initSchema$vim hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/metastore?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>비밀번호</value>
</property>
</configuration>/눌린뒤 name복사해서 붙혀넣기 한 뒤 value바꿔주기
# 오류 수정할것! 3개
1. guava 버전 맞춰주기
rm $HIVE_HOME/lib/guava-19.0.jar
cp $HADOOP_HOME/share/hadoop/hdfs/lib/guava-11.0.2.jar /usr/local/apache-hive-3.1.2-bin/lib2. 특수문자 제거
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Exception in thread "main" java.lang.RuntimeException: com.ctc.wstx.exc.WstxParsingException: Illegal character entity: expansion character (code 0x8
at [row,col,system-id]: [3215,96,"file:/usr/local/apache-hive-3.1.2-bin/conf/hive-site.xml"]
cd $HIVE_HOME/conf
vim hive-site.xml
->hive.txn.xlock.iow 검색후 들어가서 지운다.

ConnectionDriverName ->value ->com.mysql.cj.jdbc.Driver
$ schematool -dbType mysql -initSchema
// schemaTool compleated 뜨면 성공
$ mysql -u hive -p
mariadb > show databases;
mariadb > use metastore;
mariadb > show tables;
주루룩 나오면 성공
## hive 테스트
$ hive
->
Exception in thread "main" java.lang.IllegalArgumentException: java.net.URISyntaxException: Relative path in absolute URI: ${system:java.io.tmpdir%7D/$%7Bsystem:user.name%7D
에러발생시
hive-site.xml파일의
<property>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
<description>HDFS root scratch dir for Hive jobs which gets created with write all (733) permission. For each connecting user, an HDFS scratch dir: ${hive.exec.scratchdir}/<usernam
e> is created, with ${hive.scratch.dir.permission}.</description>
</property>
<property>
<name>hive.exec.local.scratchdir</name>
<value>${system:java.io.tmpdir}/${system:user.name}</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>${system:java.io.tmpdir}/${hive.session.id}_resources</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
<property>
<name>hive.scratch.dir.permission</name>
<value>700</value>
<description>The permission for the user specific scratch directories that get created.</description>
</property>
을 아래와 같이 수정한다.
<name>hive.exec.scratchdir</name>
<value>/tmp/hive-${user.name}</value>
<name>hive.exec.local.scratchdir</name>
<value>/tmp/${user.name}</value>
<name>hive.downloaded.resources.dir</name>
<value>/tmp/${user.name}_resources</value>
<name>hive.scratch.dir.permission</name>
<value>733</value>hive> 테스트
hive> create database test; -- test 데이터베이스 생성
hive> show databases;
hive> create table test. tab1 (
> col1 integer,
> col2 string
> );
hive> insert into table test.tab1
> select 1 as col1, 'ABCDE' as col1;
====> error 발생시
guava version 19.0으로 하둡의 shar/lib 과 hive/lib변경한다guava url
https://mvnrepository.com/artifact/com.google.guava/guava/19.0
출처
https://sparkdia.tistory.com/12
ubuntu version == 18.04
cd /tmp
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo dpkg -i google-chrome-stable_current_amd.deb
>>오류발생시
sudo apt-get -f install
터미널에서
google-chrome
| ubuntu 18.04 java설치 (0) | 2023.02.22 |
|---|---|
| anaconda 해당 환경 export 및 설치방법 (0) | 2021.01.04 |
$ python --version # 파이썬 버전 확인
아나콘다 가상환경 export
$ conda env export -n amazon > amazon_project.yml ## 가상환경 이름 amazon인것을 amazon_project.yml로 export
$ conda env create -f amazon_project.yml # 가상환경 amazon_project.yml 가져와서 똑같이 만들기
| ubuntu 18.04 java설치 (0) | 2023.02.22 |
|---|---|
| ubuntu Chorme 설치 (0) | 2021.01.05 |